Graceful Shutdown
Background
Kubernetes (K8s) is currently the most popular container deployment platform in the community. In the past, there have been cases where the graceful shutdown functionality of Kitex services deployed in K8s clusters did not meet expectations. However, graceful shutdown is tightly coupled with the service registration and discovery mechanisms of the deployment environment, as well as the characteristics of the service itself. The framework and container orchestration platform only provide the capability for “graceful shutdown,” but achieving true graceful shutdown relies on the overall planning and coordination of the service architecture.
With the above goals in mind, we aim to provide some corresponding solutions to address these issues from a theoretical perspective. These solutions are intended to help the community make better use of Kitex’s graceful shutdown capability in the context of a K8s architecture. Since each component in the K8s architecture is pluggable, different companies, especially those with a large number of instances, may have varying degrees of customization in terms of K8s service registration and discovery. Therefore, we will only discuss the default and most widely used K8s service registration and discovery patterns.
K8s Service Registration
Below is a common YAML configuration example for an online Pod:
apiVersion: v1
kind: Pod
metadata:
name: xxx-service
spec:
containers:
- name: xxx-service
ports:
- containerPort: 8080
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
Principle
In K8s, after a Pod is launched, it checks whether the Pod is ready to serve based on the configuration of the readinessProbe. The readiness check starts after the specified initialDelaySeconds and continues periodically with an interval defined by periodSeconds. Only when the readinessProbe criteria are met, such as establishing a connection to the container’s IP on the specified port (8080 in this example), the container’s IP is registered in the healthy Endpoints associated with the Service. This enables the container to be discovered and accessed by other services.
Issues and Solutions
Being accessible doesn’t always mean being able to provide service
In the YAML example above, we assume that establishing a listener in the business process is equivalent to the process being able to provide the service. However, in complex business scenarios, this equation may not always hold true. For example, some services may require a series of initialization operations to be performed before they can provide the service properly. If we stick to the configuration mentioned above, it is likely that when performing rolling updates downstream, we may observe errors such as timeouts upstream, indicating that the downstream service did not achieve “graceful shutdown” in practice.
To address this situation, we need to customize our health check function:
func healthCheck() {
// Perform cache warming logic
cache.Warming()
// Ensure that the database connection pool is ready
mysqlDB.Select(*).Where(...).Limit(1)
// Ensure that the necessary configurations are retrieved from the external dependency configuration center
config.Ready()
// ... Other necessary dependency checks
return
}
The prerequisite for a successful health check result is to ensure that the service is ready to handle requests.
We can register this health check function within the service. For example, if the service is using the HTTP protocol, we can configure the readinessProbe as follows:
readinessProbe:
httpGet:
scheme: HTTP
path: /health
port: 8080
If the service is using RPC protocols (such as Kitex with the default Thrift protocol) or other less common protocols, you can have the monitoring program communicate with the application through commands to check the health status. In this case, the business process, upon startup, will only create the /tmp/healthy file when the health check passes, indicating to K8s that the service is accessible:
readinessProbe:
exec:
command:
- cat
- /tmp/healthy
K8s Service Discovery
Kubernetes (K8s) uses Service as the identifier for services. Here is a common definition of a Service:
apiVersion: v1
kind: Service
metadata:
name: my-app
namespace: my-ns
spec:
type: ClusterIP
clusterIP: 10.1.1.101
Principles
Kubernetes provides the ability to translate a ServiceName into a Cluster IP using DNS. By default, the Cluster IP is globally unique and does not change with the underlying Pods. In other words, the client-side service discovery always resolves to a single IP address.
Once the client obtains the Cluster IP through DNS, it directly initiates a connection to the Cluster IP. The underlying operating system then redirects the connection to the actual Pod IP using iptables.
Issues and Solutions
Lack of Strict Load Balancing
Under the iptables mechanism, load balancing between the client and server is achieved at the connection creation stage. However, since the client only sees a fixed Cluster IP, it can only achieve load balancing across different connections and cannot control load balancing across different destination IP addresses.
If the client maintains long-lived connections and new Pods are added on the backend without the client establishing new connections, the new Pods may not receive sufficient traffic, resulting in an imbalance.
Solution
-
Use K8s headless service:
Instead of using the default Cluster IP, each service discovery returns the complete set of real Pod IPs.
This solution addresses the issue of upstream’s awareness of downstream node updates and achieves true load balancing between downstream instances.
-
Use short-lived connections with Kitex:
Create a new short-lived connection for each request, leveraging iptables' load balancing capability. This approach also solves the problem of smooth transition in which the upstream does not access the Pod that is about to be destroyed.
-
Use a Service Mesh:
Rely on the data plane to handle load balancing and delegate the problem to the data plane.
Destroying Pods in K8s
Kubernetes (K8s) provides hooks to control the behavior when destroying Pods:
apiVersion: v1
kind: Pod
spec:
containers:
- name: xxx-service
preStop:
exec:
command: ["sleep", "5"]
terminationGracePeriodSeconds: 30
Principle
When a Pod is about to be destroyed, K8s performs the following actions:
-
kube-proxy removes the target IP from upstream iptables
Although this step is generally a relatively fast operation and may not be as exaggerated as depicted in the diagram, the execution time is still not guaranteed and depends on factors such as cluster size and the level of change activity. Therefore, it is represented by a dashed line.
After this step is completed, it can only ensure that new connections are no longer directed to the IP of the old container, but existing connections will not be affected.
-
kubelet executes the preStop operation
Since the next step will immediately close the listener, it is advisable to include a sleep time (the duration depends on the cluster size) in the preStop section to ensure that kube-proxy can promptly notify all upstream components not to establish new connections to the Pod.
-
kubelet sends the TERM signal
At this point, the graceful shutdown process controlled by Kitex can commence:
- Stop accepting new connections: Kitex will immediately close the currently listened port, and any new incoming connections will be rejected. Existing connections will not be affected. Therefore, it is necessary to ensure that a sufficient waiting time for service discovery updates is configured in the preStop section.
- Wait for old connections to be processed:
- In non-multiplexing mode (short connections/long connection pools):
- Check whether all connections have been processed every 1 second until there are no active connections, then exit directly.
- In multiplexing mode:
- Immediately send a control frame (a thrift response with seqID 0) to all connections and wait for 1 second (waiting for the client on the other end to receive the control frame).
- When the client receives this message, it marks the current connection as invalid and stops reusing it (the ongoing send and receive operations are not affected). The purpose of this operation is to ensure that the client no longer sends requests on existing connections.
- Check whether all existing connections have been processed every 1 second until there are no active connections, then exit directly.
- In non-multiplexing mode (short connections/long connection pools):
- If the Kitex exit wait timeout (ExitWaitTime, default 5 seconds) is reached, exit directly regardless of whether old connections have been processed.
-
If the terminationGracePeriodSeconds set by K8s is reached (counting from the time the Pod enters the Termination state, including the time to execute preStop), send the KILL signal to forcefully terminate the process, regardless of whether the process has finished processing.
Issues and Solutions
Client Cannot Detect Closing Connections
This problem is similar to the underlying issue of load balancing during service discovery.
When a downstream node begins to be destroyed, the client relies entirely on kube-proxy to promptly remove the corresponding Pod IP from the iptables on the machine. The client itself continues to create connections and send requests to the ClusterIP without interruption.
Therefore, if kube-proxy does not remove the IP of the destroyed Pod in a timely manner, connection creation issues may arise. Even if kube-proxy removes the rules corresponding to the Pod IP, existing connections will not be affected and will still be used to send new requests (in the case of long-lived connections). In this scenario, the next time this old connection is used, it may collide with the situation where the Pod on the other end is being closed, resulting in errors such as connection reset.
Solution
-
Use a K8s headless service:
When the offline IP is unregistered, the upstream Kitex client will automatically stop assigning new requests to that IP. As the subsequent server is also shut down, the upstream connections will naturally be closed.
-
Use a Service Mesh:
In a Mesh mode, the control plane takes over the service discovery mechanism, while the data plane handles the graceful shutdown process. This frees the upstream application from the details of service governance.
Server Cannot Finish Processing all Requests before Shutdown
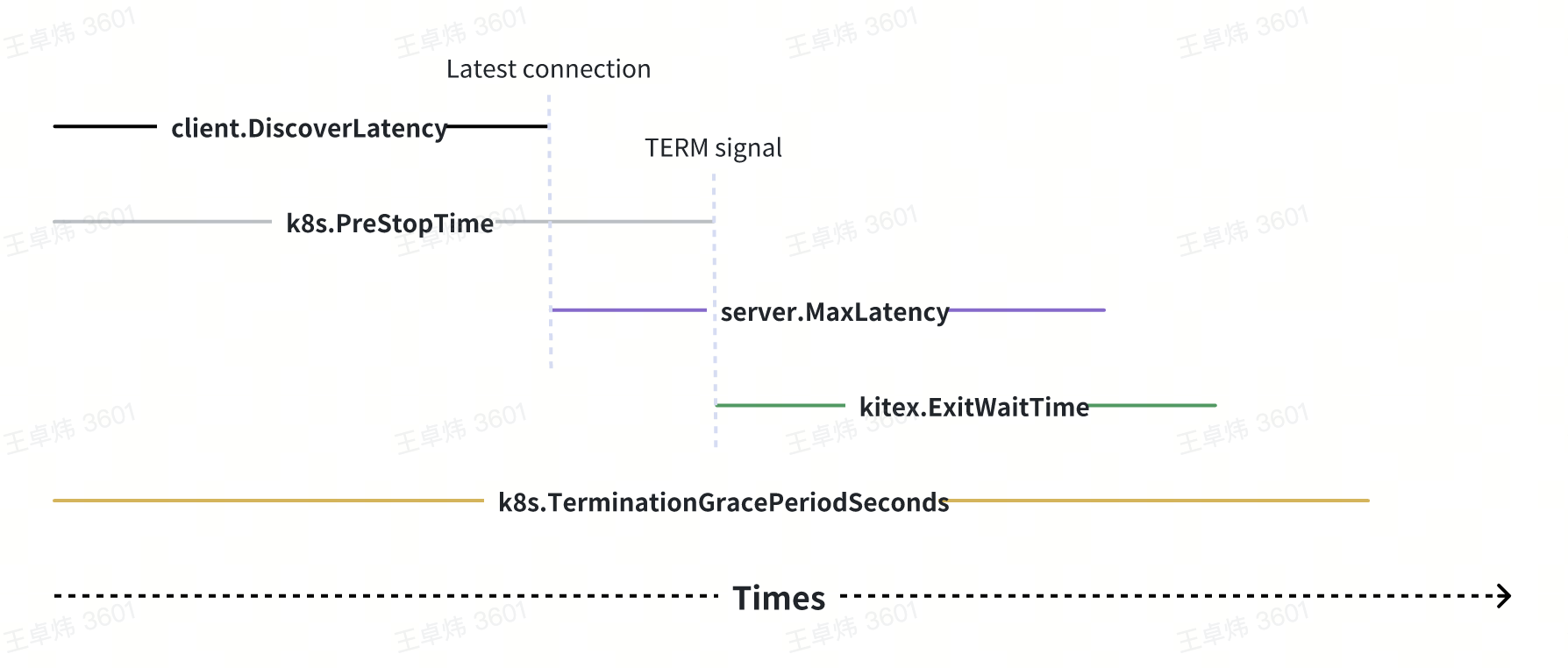
This problem fundamentally depends on several time durations:
- Upstream service discovery update time (client.DiscoverLatency)
- K8s preStop waiting time (k8s.PreStopTime)
- Maximum processing time for downstream service requests (server.MaxLatency)
- Exit wait time for the Kitex framework (kitex.ExitWaitTime)
- K8s terminationGracePeriodSeconds
These durations must strictly follow the size relationship depicted in the sequence diagram. Otherwise, the graceful shutdown may not be achieved:
Summary
Through the complex process described above, it becomes evident that Kubernetes (K8s) and the Kitex framework only provide parameters to enable users to achieve graceful shutdowns. They do not guarantee the automatic implementation of graceful shutdown in all types of services and deployment environments. In fact, it is not possible to achieve such a guarantee.
Furthermore, while it is feasible to achieve near 100% graceful shutdown for each specific service, it is rare to have enough resources to individually configure parameters for every service on a global scale. Therefore, in real-world scenarios, we recommend understanding the principles of each component in the system and, based on the overall characteristics of the business, configuring a relatively broad and secure set of default parameters for graceful shutdown. For extremely critical services with unique latency requirements, specific parameters can be considered.
Finally, upstream services should not assume that downstream services will always achieve 100% graceful shutdown. Upstream services should also implement capabilities such as retrying with alternative nodes in case of connection failures to shield against small-scale node fluctuations and achieve higher SLAs.